There was a time when websites were filled with similar content in order to manipulate search rankings. Websites published the same content on multiple pages to increase their chances of ranking for a specific topic.
Search engines like Google caught onto this, and they started using algorithms for identifying pages with similar content. In the language of SEO, we call this content “duplicate content.”

In this article you’ll find answers to the following
- What is duplicate content?
- How duplicate content is created?
- How to find duplicate content?
- How to fix duplicate content?
What is duplicate content?
Duplicate content is content that is published more than once on the web. Every webpage has a unique URL, and duplicate content is present in multiple URLs.
Essentially, if the same content is present on more than one URL, this content will be referred to as “duplicate content.”
Can this content result in a penalty?
Usually, duplicate content will not result in a penalty unless your website is filled with duplicate or copied content. This content can rarely earn you a penalty, but it can affect your website’s search engine rankings.
When the same content is present on multiple locations on the web, search engines find it difficult to rank these pages in search results of a query. Deciding which web page to rank and which to leave can get tricky for search engines, and it can affect a web page’s chances of getting ranked.
Google defines this content as “appreciably similar.”
Why is learning about duplicate content essential?
Duplicate content can cause issues for both search engines and website owners. Learning about duplicate content is essential to prevent these issues. This article will cover all the possible problems this content can cause for website owners and search engines.
Problems for search engines
There are three main issues that duplicate content can cause for search engines.
- Search engines find it difficult to choose between different web pages for the purpose of indexing.
- They have difficulty in deciding which page to rank in the search results.
- They are confused about whether to direct link metrics to one of these web pages or all of them separately.

Problems for website owners
Duplicate content causes website owners to lose traffic and rankings. These problems are caused because
- Search engines avoid ranking multiple pages with the same web content in a search result. Which forces the search engines to choose between different web pages with similar content, decreasing the probability of these web pages ranking in search results.
- The link equity of these web pages is diluted even more because websites also have to choose between these web pages. The inbound links point to multiple pages instead of one, causing the link equity to get divided among various web pages.
Inbound links play a vital role in the ranking of a web page, division of the link equity can adversely affect the search engine rankings of a web page.
A web page will never reach its full potential if its content is marked as “duplicate content.”
How duplicate content is created?
Why content gets marked as being “duplicate content.”
Typically, website owners don’t have an intent of creating duplicate content. But this lack of intention doesn’t mean that the internet is free of duplicate content.
According to some reports, close to 28.9 percent of the content present on the internet is duplicate. Here are some of the common ways in which duplicate content is unintentionally created.
Scraped content
Scraped content not only refers to articles and blogs that are word to word copied with malicious intent. But it also refers to similar product descriptions published on multiple web pages. Many e-commerce websites source products from the same manufacturer, and they use the product description provided by the manufacturer.

You may think that scraped content is the content stolen from other websites, but it is not always stolen content that gets categorized as scraped content, as you may have noticed in the example above.
Separate versions of a website (HTTPS, HTTP, WWW)
Many websites have different versions, for example, www.yourwebsite.com and Yourwebsite.com. The only difference between these two versions is the www prefix. Both these versions of a website host the same content. It means that both these versions are duplicates of each other.
Some websites hold different versions for HTTP and HTTPS. When both these versions are indexable for search engines, these engines will mark this content as duplicate content.
Variations in URL
Some URL parameters can cause the content to be marked as duplicate. One of these parameters is click tracking. The nature of these parameters is not the sole reason for the duplicate content issue, but the order in which these parameters are arranged can also cause this issue.
Here’s an example
www.yourwebsite.com/shoes?type=sneakers will be considered a duplicate of www.yourwebsite.com/shoes?type=sneakers&sortprice
The same goes for
www.yourwebsite.com/widgets?color=blue and www.yourwebsite.com/widgets?color=blue&sort=newest
Sessions IDs can also be regarded as duplicate content. It mostly happens when a visitor is assigned a unique session ID stored in the URL.
Your website may also have print-only versions of multiple web pages. Most big websites have these print-only versions. These print-only versions can also cause a duplicate content error if they are indexed.
According to SEOs, URL parameters should be avoided when possible. Alternate versions of URLs should also be avoided to save our web pages from duplicate content errors.
Now that we have learned enough about duplicate content and the causes of its presence, let’s move onto identifying duplicate content.
How to find duplicate content
Identifying duplicate content
The most common reason why duplicate content problem pops up is the automatic creation of different URLs holding the same content.
Typically, this problem occurs with e-commerce websites.
In the best-case scenario, all the variations of a product are present on the same web page. These can include variations in color, design, and size.
Sometimes, a website automatically creates different web pages for each of these variations. A product can come in several different colors and styles, and this automatic web page creation can create thousands of duplicate pages.
Search result pages can also get indexed for the websites with a search function. It can also generate thousands of web pages containing duplicate content.
Going through indexed pages
The easiest way of finding these automatically generated web pages is to go through the indexed web pages of your website.
Just search for site:yourwebsite.com
Google search console also contains a list of indexed pages. You can also use it for checking out your indexed pages.
This number should match the number of web pages you have manually created for your website. If you find that indexed web pages are considerably higher than the original number, your website automatically generates web pages.
For example
You have manually created 1200 web pages. The Google console search results show that your website has a total of 13000 web pages. It is an indicator that your website contains a lot of duplicate content. Automatically generated pages are vastly composed of similar/same content.
How to fix duplicate content?
Canonicalizing web pages containing similar content is the only way of avoiding a duplicate content problem.
There are two commonly used methods of doing this. The first one is
301 redirect
You can set up a 301 redirect to redirect to the original content from pages containing duplicate content. It means that you should combine different pages into one page. It increases the chances of a better ranking for the original page.

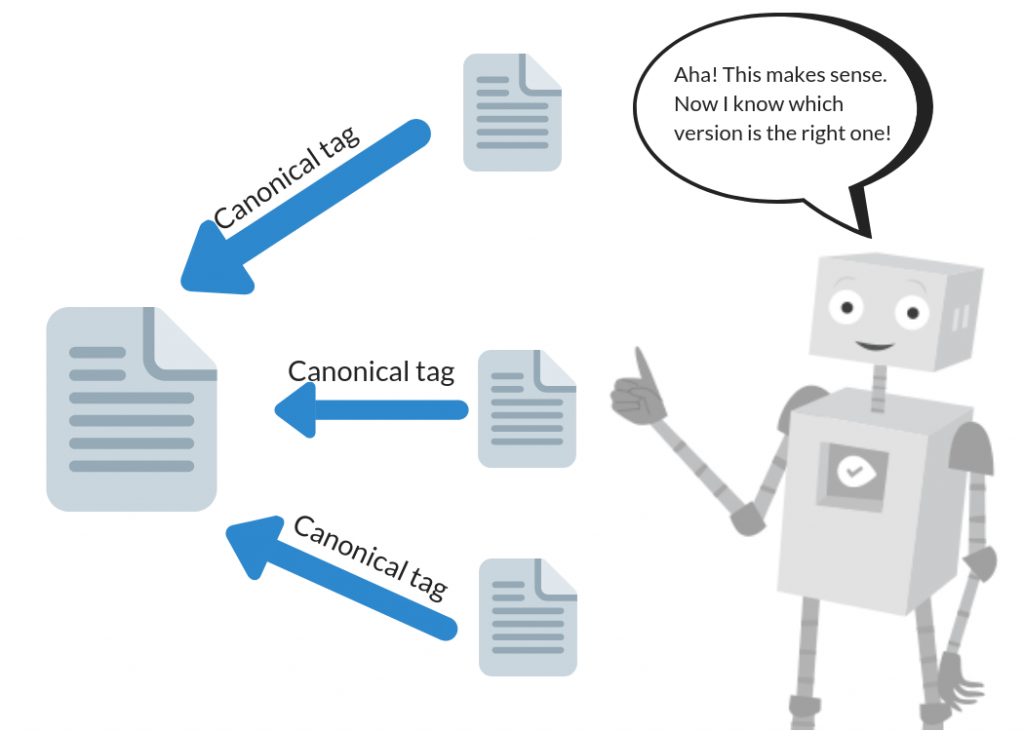
A rel=canonical tag
A rel=caonical tag helps search engines identify the pages that should be considered a copy of the original content. It means that all the ranking power of this page will be credited to the original URL.
This tag is added in the Head of the HTML document of duplicate page. Adding this tag is reasonably straightforward, and you can do it within a couple of minutes.
Bottom Line
The duplicate content error can be very annoying for many website owners. Still, this error is caused by the same algorithm that prevents other websites from earning money through stolen or scraped content.
Some website owners intentionally create duplicate content, but most of us do not. Duplicate content can be created due to several reasons, and we’ve covered them all in this article. Search engines like Google also provide many ways in which website owners can avoid duplicate content errors.
The most common methods of avoiding this error are using a 301 redirect or a rel=canonicalize tag.
Is there a difference between the number of web pages you have manually created on your website and the number of web pages that are indexed by search engines?